
AI/LLM based approach
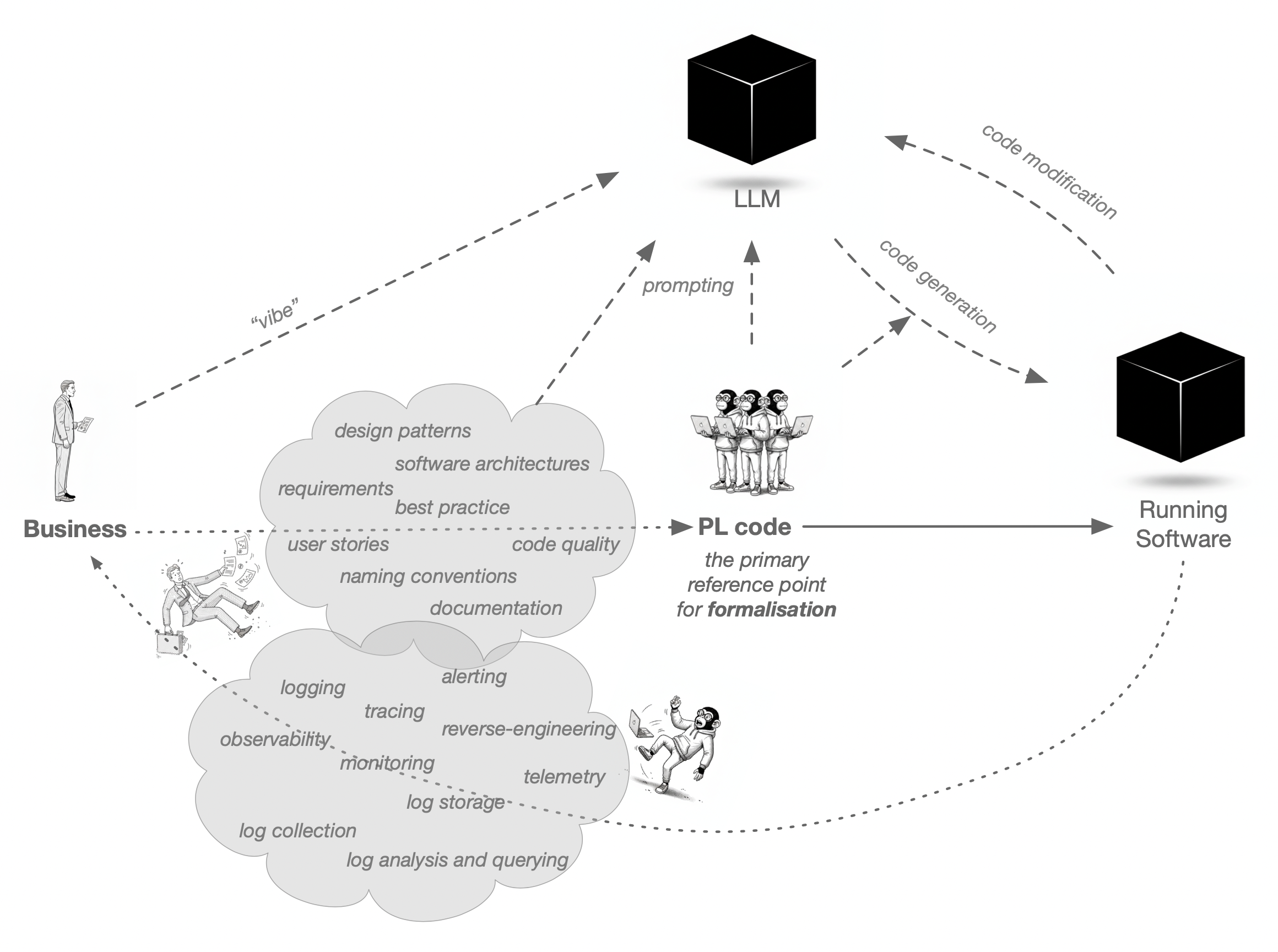
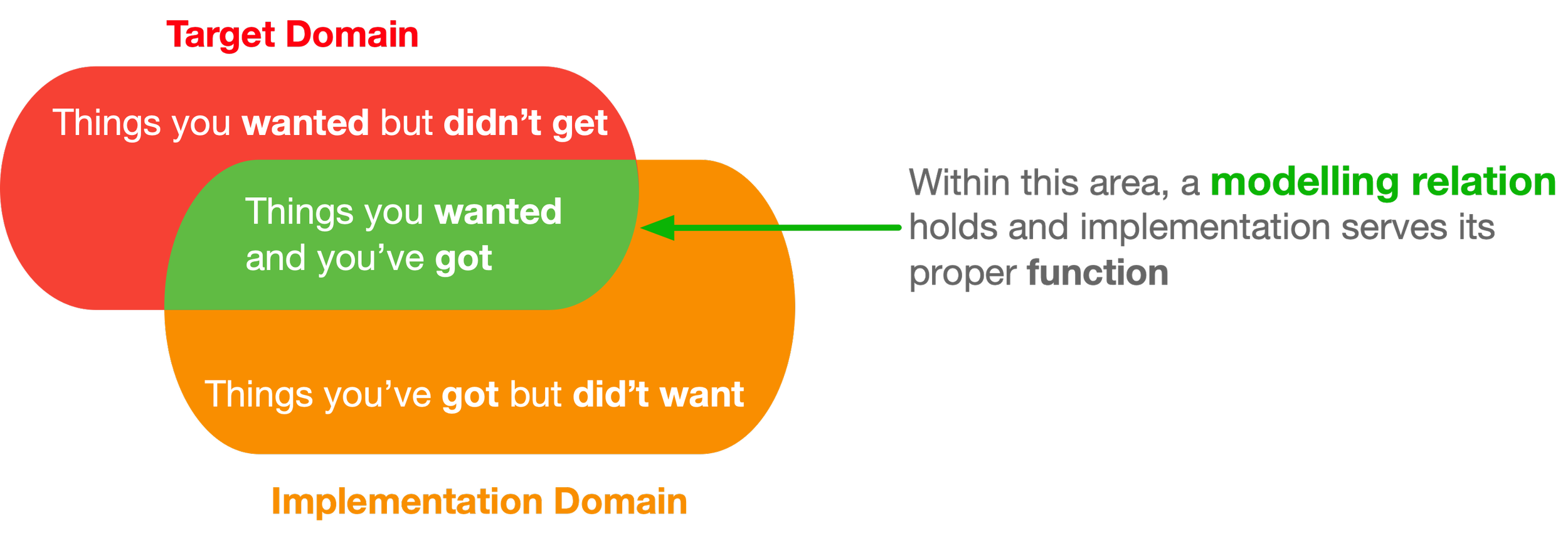
Using general-purpose LLMs directly introduces two kinds of problems: “things you wanted but did not get” and, especially, “things you got but did not want.” Both are artificial issues introduced by the tool itself, turning an initial target-domain problem into a much larger and more complex one. Taking DCM as the starting point minimizes these negative effects while still allowing ANNs to be applied on top of it where appropriate.
The amount of computational power and cost required to implement, for example, trade settlement via LLMs would be many orders of magnitude higher than doing so with DCM—even if that computation is hidden on the provider side and appears inexpensive at first.
Although LLMs may initially create the impression of a silver bullet—promising to “build software for free” with no engineering effort (prompt engineering is not engineering in the strict sense, but rather a situational skill that offers no full control over the results)—the lack of control and reliability, combined with the incommensurable complexity of the overall solution hidden under the hood, amplifies unconstrained risks in the long run. The result may be damage caused by unpredictable or unwanted behavior, as well as disproportionate effort required to diagnose and correct such behavior.
A target domain whose underlying logic is fully deterministic effectively becomes probabilistic when implemented through LLMs; one can never be entirely certain how such a system will behave in future, especially after it has undergone numerous changes.
The way modifications and changes are handled in LLM-generated software introduces another source of problems that may not be visible initially: the accumulation of errors or side effects, increasing the risk of erroneous behavior as the system grows in size and operating time.
Furthermore, LLMs operate by generating code, which reflects a problematic early move into the implementation domain. This forces one to address the target domain from within the programming-language layer—whether through a human engineer or an LLM agent—thereby reintroducing the very problems that arise when programming directly in a PL.
By contrast, DCM takes an approach in which no programming-language code is generated. Instead, the products of inference remain at the level of the target domain itself. This is possible because the core system operates at the level of structured world models rather than predicting sequences of structureless tokens.
In principle, it would be possible to train an ANN to operate over something like DCM at the foundational level, but that would be fundamentally different from current general-purpose LLMs such as Claude and similar systems.
The illusion of an easy start
Generating output (e.g., code) is only the first step in operating a software system. Cutting corners at this stage comes at the cost of introducing problems in later stages.
As the diagram below shows, it is easy for generative models to produce output that is statistically close to the prompt.
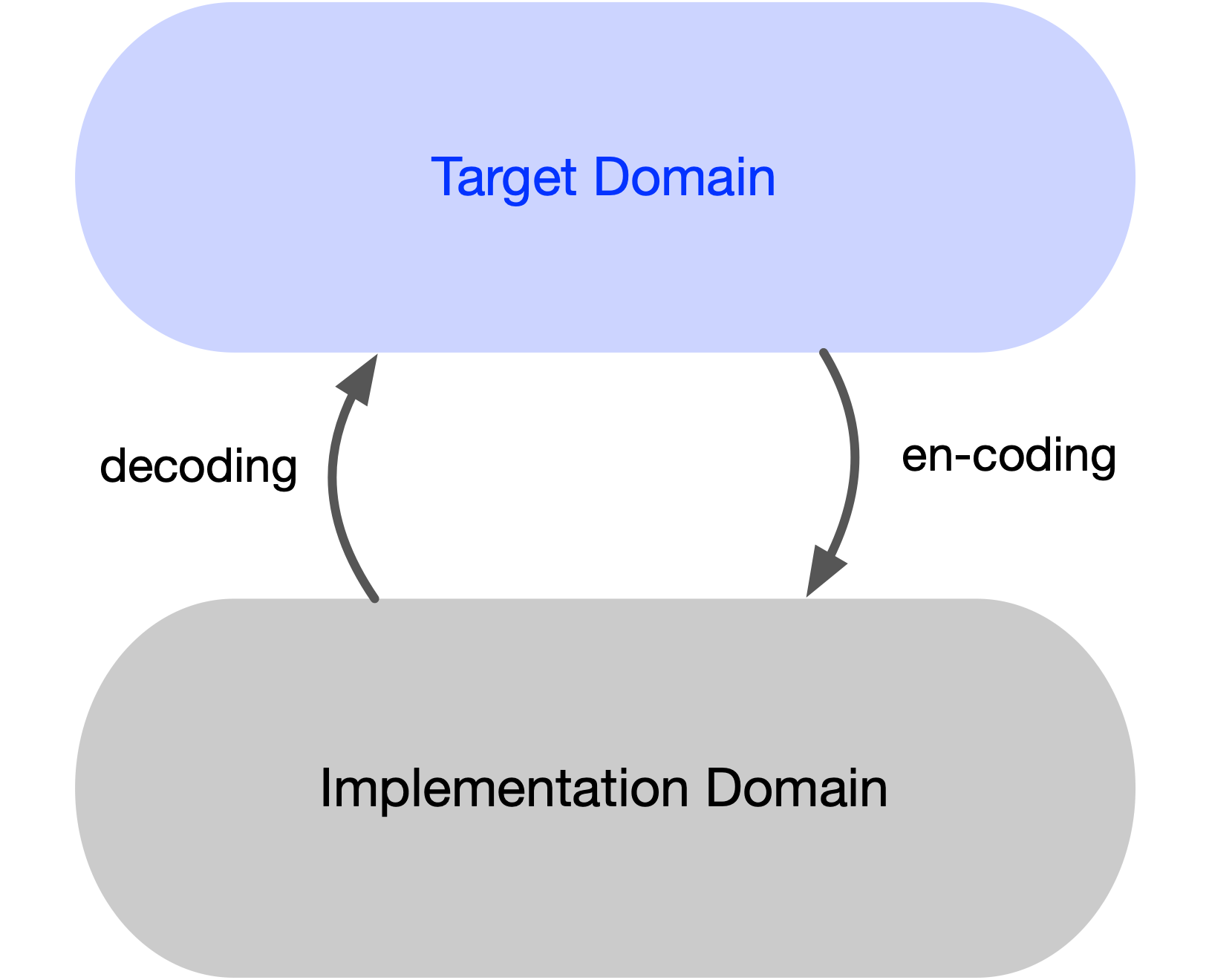
However, each time the generated output needs to be adjusted (i.e. controlled), it must be decoded by the same ANN into its internal abstract weight space.
There is no guarantee that this decoding will commute with the original encoding—that is, the output may not map one-to-one to the original prompt. Even a single encoding–decoding cycle may fail to commute, due to the way LLMs operate by design.
Now consider that this encoding–decoding cycle may be repeated thousands of times, as is typical in the change and support cycles of a software system. With each iteration, drift away from the original prompt increases, and side effects accumulate without becoming immediately visible.
After many such cycles, the resulting system may become unpredictable, with no reliable way to ensure that it still preserves any modeling relation to the target domain—even if it did so initially.
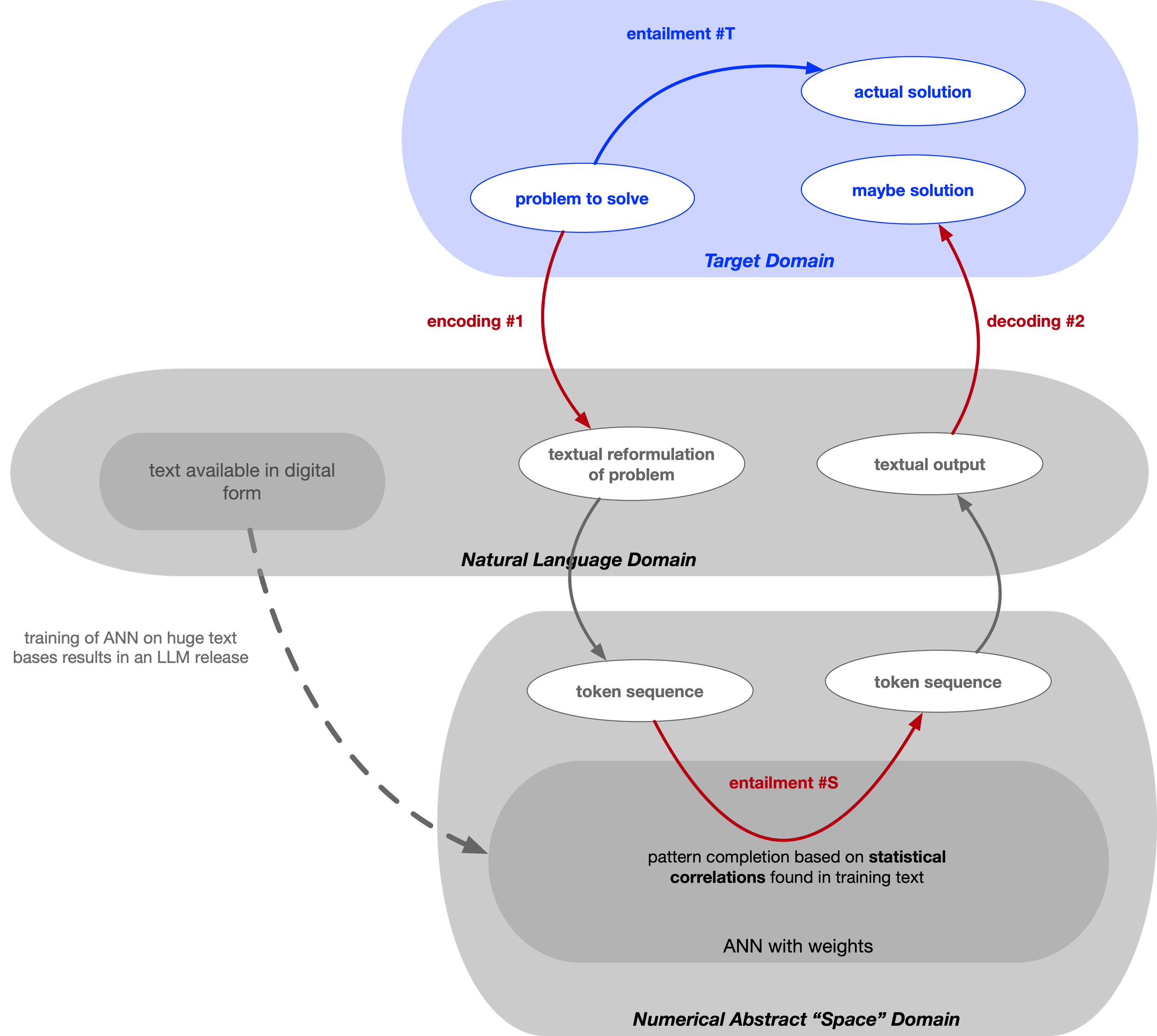
The simplified diagram illustrates where the problem arises when applying LLMs to a target domain that differs significantly from natural language—such as contract management.
The first issue is that LLMs require an additionalencoding of the target-domain problem into natural language, followed later by a decoding of the solution back into the target domain. This step can lead to information loss and the introductionofnoise during both encoding and decoding. In particular, when the target domain is a formal system without ambiguity, such one-to-many encodings introduceambiguity that will accumulate and eventually backfire.
An even more serious problem is the lack of correspondence between entailments in the target domain (#T-entailments) and entailments within the LLM domain (#S-entailments). Hallucinations are an example of latent (invisible to the user) entailments within the LLM that can leak into the target domain in unpredictable ways.
Furthermore, there is no reliable way to determine in advance whether such correspondence holds, nor is there a predictable method for establishing it. In addition, an LLM cannot reliably acquire fundamentally new structural patterns after training.
Both of these problems—the encoding/decoding issue and the correspondence issue—are introduced artificially by the use of general-purpose LLMs instead of domain-specific models such as DCM.
These problems can themselves be addressed by introducing even more complexity into the overall system (such as so-called multi-agent AI architectures), but such solutions come with their own costs and risks. As is often the case, preventing errors in one part of a system merely shifts the risk elsewhere rather than eliminating it altogether.
An analogy comparing DCM vs. PL vs. generative AI (ANN)
when posed with a question of “Why did a certain behaviour (e.g. activity or an error) happen“
DCM : Cognitive level as intermediate
DCM is not based on ANNs, but on a model of cognition — more traditionally, a model of reasoning.
Human reasoning is underpinned by neural networks in the brain, but when solving conceptual (rather than perceptual) problems, there is no need to descend to that level, just as one does not need to descend to the hardware level of transistor voltages when writing code in programming languages.
DCM sits between the ANN level and the natural-language level — the very cognitive level that LLMs skip.
LLMs take shortcuts, generating outputs directly from ANNs with uninterpretable internals.
LLMs are built to answer almost any query in natural language.
In comparison, DCM targets a much more limited domain and does not operate at the level of natural language, but rather on a much smaller underlying cognitive model (a kind of sub-language model of cognition).
LLM : Chinese room simulation of the form
From a business perspective, DCM is like a glass box thanks to semantic transparency. If you ask “why,” you see the answer directly—in business terms.
These terms correspond closely to how a human would think about the matter, because DCM is grounded in evidence from cognitive sciences that study this very process in humans.
Moreover, since DCM models are multi-paneled—capturing multiple levels of reality—there will be several answers, one per level, much like several Aristotelian causes.
Every step in the behavior of DCM-driven code can be traced back to all of its causes—both retrospectively and prospectively when anticipating future actions.
Glass Box (DCM)
Black Box (PL)
The traditional approach to coding business applications with programming languages produces a black box. If you ask “why,” you must build special mechanisms to inspect what’s happening inside and report the status of technical machinery back.
That kind of answer corresponds to Aristotelian immediate cause.
Anything above this low technical layer has to be reconstructed in an ad hoc manner.
Even at this technical level, you can only trace the behavior of your code if that code implements explicit logging of its behavior.
There is no way to trace prospective behavior—you don’t know what will happen until the code is actually executed, since it is a purely reactive system.
Black Hole (ANN)

You cannot meaningfully ask “why,” because the same ANN will treat your question as an independent query and fabricate a plausible answer instead of revealing the actual way the original answer was generated. An ANN is unable to reflectively track its own inner workings and report on them.
Furthermore, even if it could, patterns in the so-called abstract space of ANN weights do not necessarily correspond to those formed by the human brain, and the same answers could have been produced through a very different generative process—one that might appear completely alien or illogical to a human (logic).
If something ever goes wrong, you might not be able to trace it to a root cause, because not only will there be no single element in the ANN that can be pointed to, but the behavior in this case also cannot be traced back to reveal or simulate why it was decided one way and not another.
LLMs do not act or reason as organisms do. They are not cognitive in this sense.
Instead, they rely on brute force: first building a massive set of token-based patterns from extremely large datasets (text or images). These datasets are heavily preprocessed (e.g. data cleaning) and then fed into enormous ANNs to form attractors in their abstract parameter space, which are then used to pattern-complete token-based queries.
This is somewhat like training, in a laboratory, a structurally primitive but enormously large artificial, disembodied “brain” whose only access to the world is through tokens spoon-fed to it.
Then this “brain in a vat” is asked questions (in the form of text tokens) and generates replies (again, only in text tokens).
While this can go very far in modelling language as possible forms that tokens could take, there is nothing to enforce that the underlying meaning or semantics (what language evolved to express in the first place) get captured in the attractors formed in the huge space of ANN parameters after training on massive text corpora.
The situation with LLMs is somewhat similar to the Chinese room experiment, where the LLM acts like a person locked inside a room who does not understand any Chinese, but is still capable of reproducing fluent Chinese by matching the strange symbols on the incoming paper to instructions in an English manual.
The LLM is a model of language, not a model of meaning or reasoning.
An LLM is a highly effective simulation of linguistic form that can capture meaning only indirectly, as a by-product of capturing the form in which meaning is expressed through language.
DCM is deterministic: it describes effects in terms of their causes (diachronic, deep).
By contrast, LLMs are statistical: they simulate effects without knowing or modeling their actual causes (synchronic, surface-level).
LLMs draw content from extremely large datasets and are designed to provide a plausible answer to almost any question.
By contrast, DCM is focused on a very small set of constructs and operations that possess high inferential potential, where the content must be explicitly provided by the users.
Most of the prime elements of DCM are absent in LLMs as such : an explicit space–time mereotopology, forces, the separation between actual plane and the information plane, and so on. All of these are directly understandable by humans because they are modeled after human cognition in the first place.
LLMs, by contrast, operate in their own “abstract space,” which is uninterpretable and has no direct relation to the space–time topology of the world humans inhabit.
For an LLM to solve the same kinds of problems DCM addresses, it must consume orders of magnitude more resources and work (both at design time and runtime) because it does not start at the right level—it lacks the cognitive layer (the level between natural language and neural substrate).